That Time I Thought I Needed an Agentic Solution but I Really Didn't
In this blog post I’m going to talk about a time I really thought I needed to implement an agentic solution to solve an LLM related problem but it turned out that I really didn’t. Let me first describe the problem itself. I was building HinterviewGPT where there was one feature where the user could generate a practice interview question for themselves based on a description they provide. Specifically, there was a chat ui on the left half of the page where the user can chat with an LLM about the topics/industries etc. that they are interested in and once the LLM (GPT-4o in this case) has enough information it would generate a relevant interview question on the right side of the page. Initially the page looked something like this.
At first glance it seemed like a simple task from an LLM standpoint - just feed the conversation history into a prompt along with some instructions to generate an interview question based on the conversation. And this did work, sort of. For example here is an example that works fine.
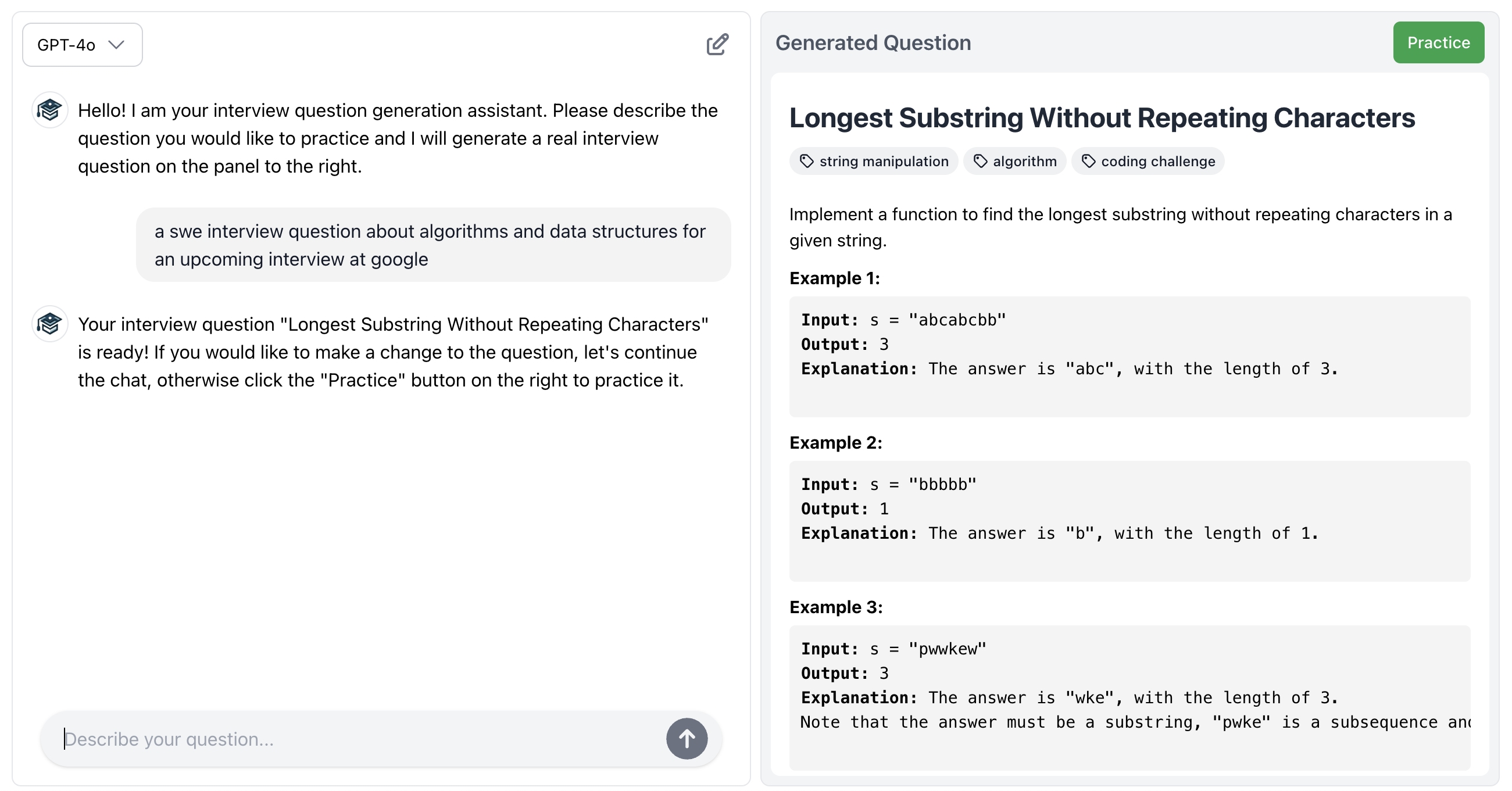
Notice how the generated interview question is nicely formatted HTML (this will come into play later). However, if you think about this task a bit longer, you might discover that there are some tricky edge-cases.
This is actually trickier than it seems…
The tricky edge-cases are the following.
- What if the user types something that is not related to generating a question but rather to get a response in the chat ui.
- What if the description the user provides in the chat ui does not contain enough information for the LLM to generate an interview question.
The first edge case occurs when the user writes something in the chat ui like “How does this work?” or “Thanks for generating this question” or “Wow this question you generated is terrible” or “ksflkjdslkjflkdjflkds” - in these cases the LLM should not actually generate a question but rather respond to the user within the chat ui. So we have to somehow predict whether the users intent is to generate a question or to receive a response in the chat ui and proceed accordingly.
The second edge case occurs when the user writes something in the chat ui that is intended to generate a question but, according to the LLM, it does not contain enough information to actually generate a high quality question. In this case obviously no question would be shown on the right side of the page and instead a message should be displayed to the user in the chat ui explaining that they need to provide more information.
Agentic solutions to the rescue?
My first thought was that this was the perfect candidate for an agentic solution. The workflow could be the following: The user inputs their message on the chat ui side, then an “intent” agent could decide whether the user actually wants to generate a question based on the message or if their intent is something else (i.e. edge case 1). If the agent decides that the intent is to generate a question, then it calls a “question generation” agent which would actually generate a question. If the intent was decided to be something else, then it calls a “follow up” agent which responds to the message without generating a question. But this still leaves edge case 2, when there is not actually enough information to generate a high-quality question. This can’t really be known until the “question generation” agent has been called, so we add another “question validation” agent after this which determines if the question was successfully generated - if so the question is shown on the right side of the page, if not a message is sent to the user on the chat ui. Here is a visual overview of the agentic system.
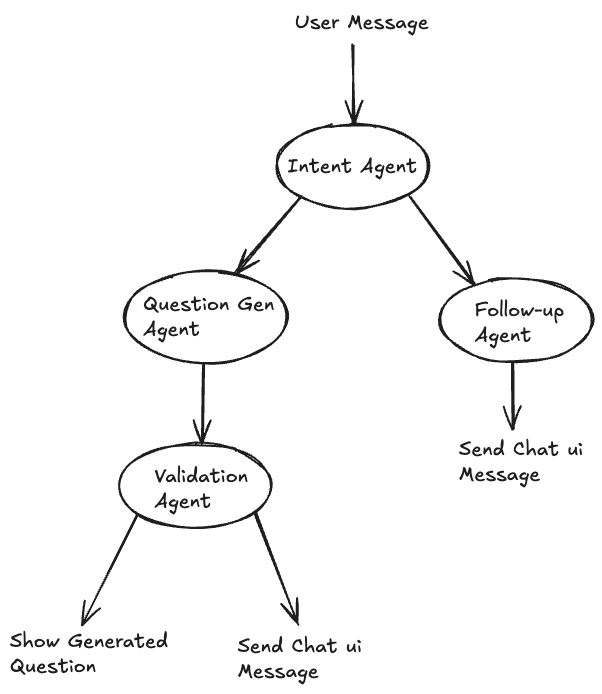
I implemented this setup and it worked, more or less. There were occasional issues related to misclassifications of the agents which resulted in situations where a generated question would incorrectly show up in the chat ui or where follow-up questions would incorrectly show-up in the question display area - but this could be mitigated for the most part with some careful prompt engineering. Also, of course, the agentic setup increased latency, cost and complexity.
… but then it hit me that I had way over-engineered this and there was a far more optimal solution that was much simpler.
Oops, I really didn’t need an agentic solution after all
Remember at the beginning of this blog post when I said that the generated question was instructed to have nicely formatted HTML? Well, it turns out that was actually the answer to both my edge cases that I was concerned about. Let me explain. Say there’s a single LLM API call where we pass in the conversation history and some instructions indicating that the LLM should generate a question with nicely formatted HTML. What would happen if the conversation history did not contain enough information to generate a high-quality question (i.e. edge case 2)? The LLM would respond indicating that this is the case in plain text i.e. not using HTML formatting. Similarly, if the user’s message does not contain the intent to generate a message the LLM would not generate a question and respond in plain text. Based on this observation, a much better solution is to simply have one LLM call and if the response contains HTML tags then this implies that a question has been generated and it should therefore be displayed in the generated question area. If the response does not contain HTML tags, then this indicates that the response should be displayed as a message in the chat ui. Also, obviously, determining whether a string contains HTML tags can be done deterministically without the need for an LLM call. For example, in Typescript
function containsHTMLTags(input: string): boolean {
// Regular expression to match HTML tags
const htmlTagRegex = /<\/?[a-zA-Z][^>]*>/;
return htmlTagRegex.test(input);
}
This is the strategy I ended up going with and it was lower latency, cheaper and less complex than the agentic approach I outlined above. Here is an example of an edge case being handled correctly using this strategy.
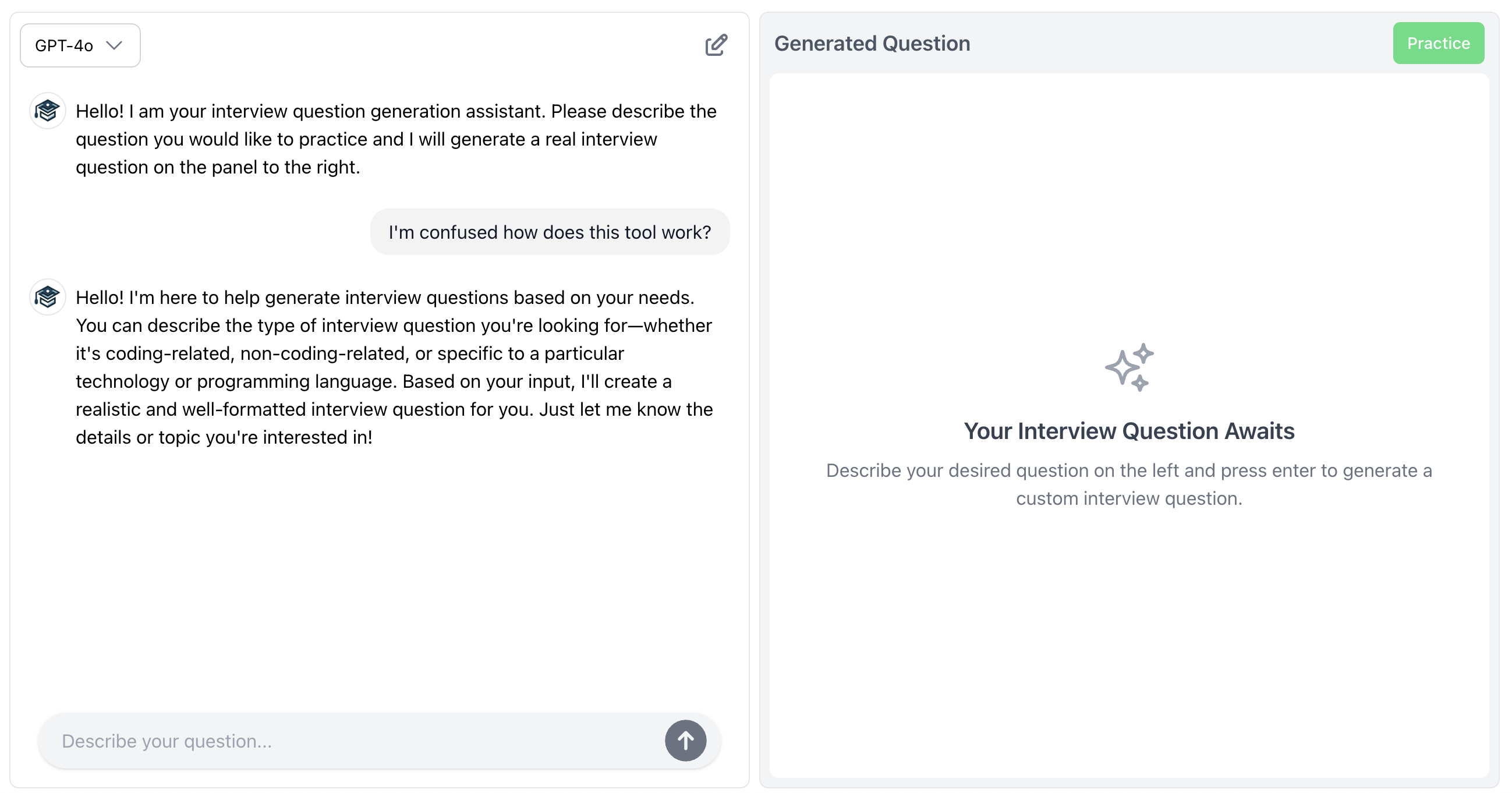
Notice how the system knows that the response from the LLM does not contain HTML tags therefore it is a response that should be displayed in the chat ui.
Lessons learned
I learned a few lessons here. 1) Not every complicated problem involving LLMs requires an agentic solution. More specifically, most LLMs handle edge cases in their inputs quite elegantly out-of-the-box. 2) Specifying a distinct output format to the response (e.g. HTML) can have an added benefit - you know if the LLM was successful if the response is in the specified format or unsuccessful if it is in plain text. Sort of like an implicit classification that LLMs give you for free. In retrospect a lot of this seems kind of obvious but it definitely didn’t seem that way when I was working on it.
UPDATE:
I recently tried the above with some reasoning models (o1-mini and o3-mini) and it didn’t quite work the same
way. Specifically, when these models were not able to generate interview questions they actually still responded
in valid HTML, which is not the behavior of GPT-4o. However, this was fairly easily solved by adding some text to the prompt
to explicitly tell the LLM to respond in plain text if a question could not be generated. So even with this difference
it still stands that an agentic solution was not needed.